

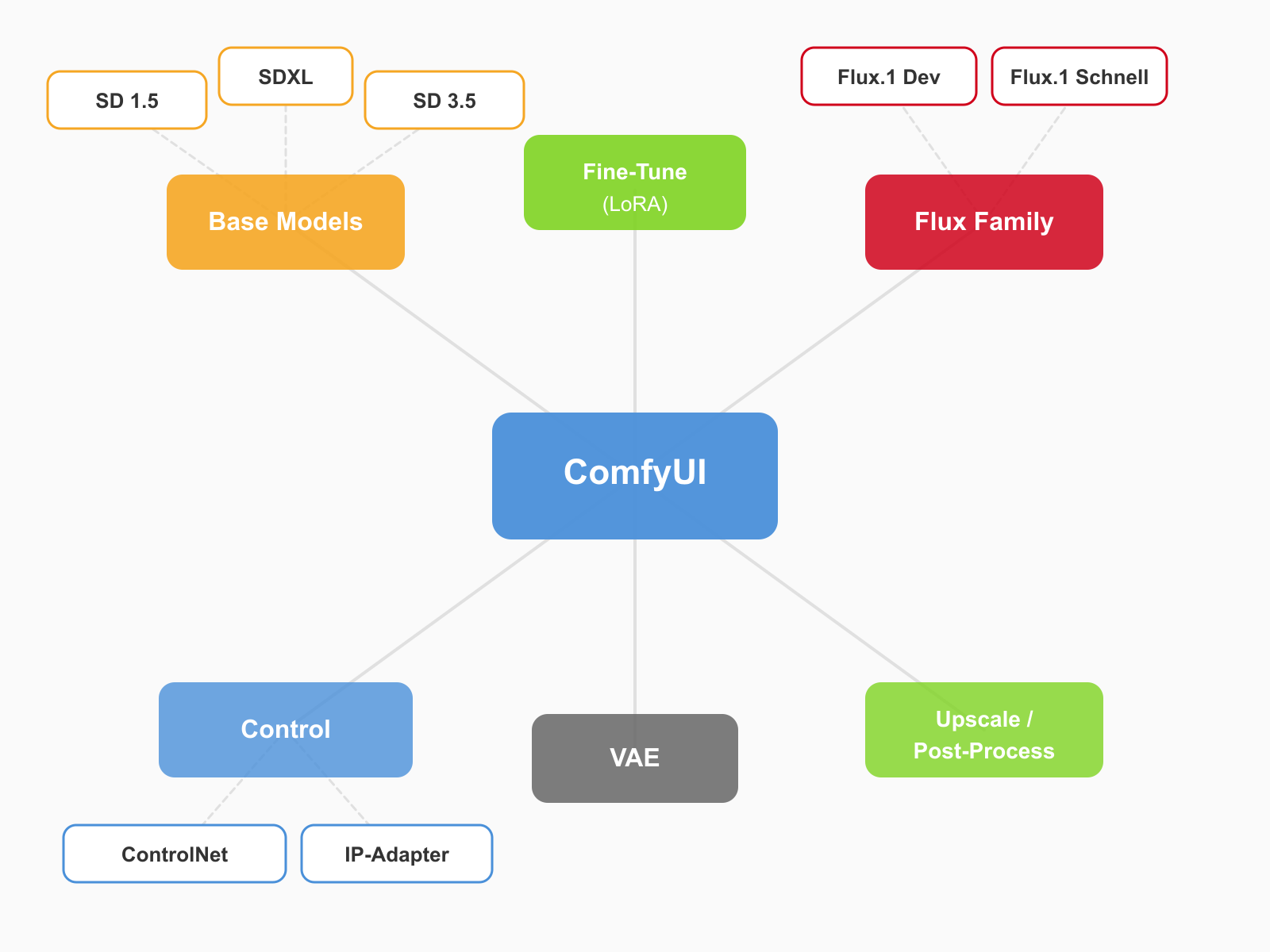
요즘 AI 이미지 생성 쪽에서 ComfyUI 안 쓰는 사람이 거의 없음. 근데 처음 시작하면 모델이 너무 많아서 뭘 써야 할지 감이 안 잡힘. Stable Diffusion 1.5, SDXL, Flux, ControlNet, LoRA... 이름만 들어도 머리 아픔.
그래서 ComfyUI에서 실제로 많이 쓰는 오픈소스 모델들을 한번에 정리해봤음. 각 모델이 뭔지, 언제 쓰는 건지, 뭐가 다른 건지 핵심만 짚어줄 거임.
Stable Diffusion 1.5 — 레전드의 시작
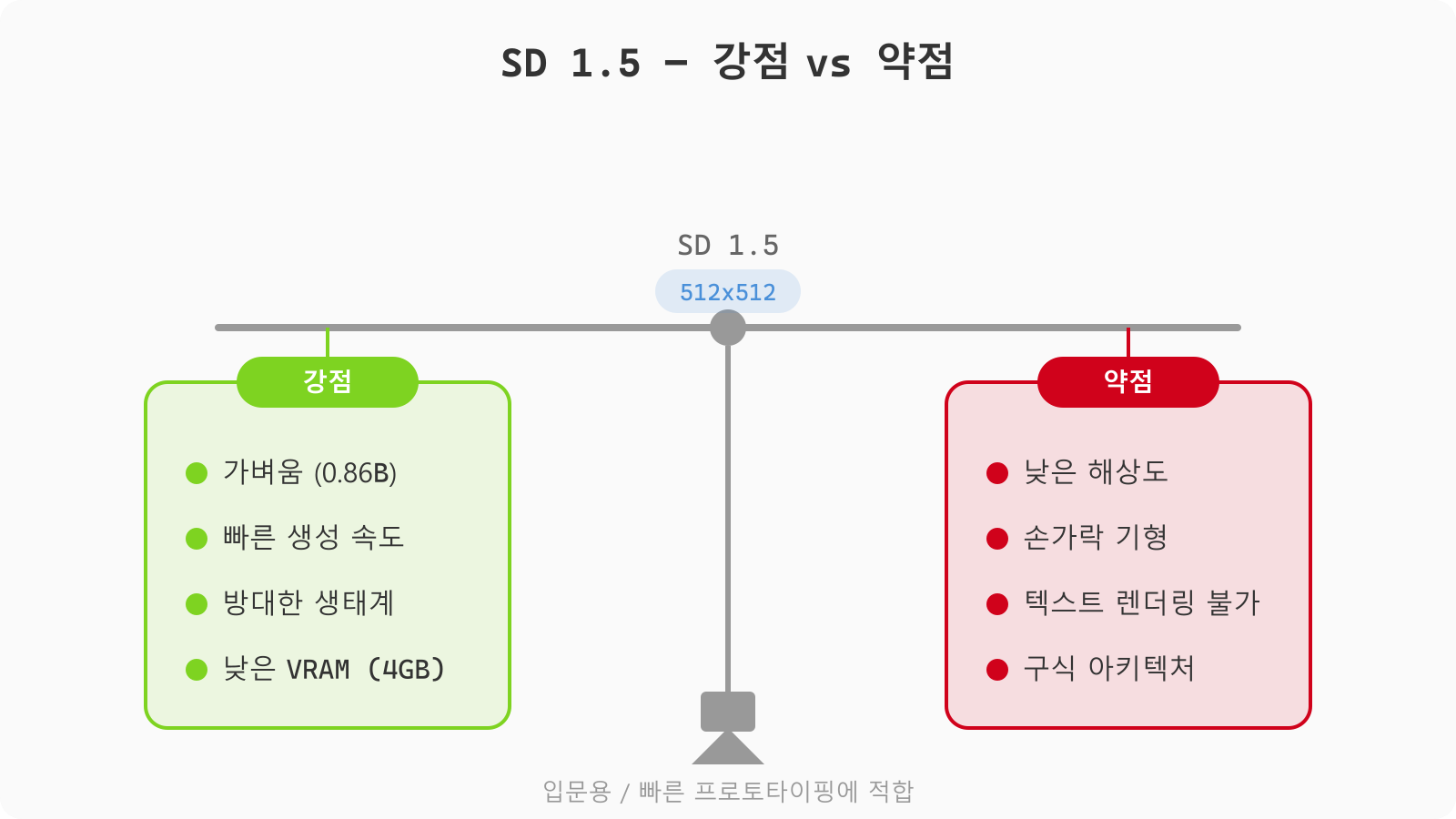
SD 1.5는 2022년에 나온 모델인데, 아직도 쓰는 사람이 꽤 있음. 이유는 단순함. 가볍고 빠름.
- 파라미터: 약 8.6억 개
- 해상도: 512x512 기본
- VRAM: 4GB면 돌아감
- 생성 속도: 가장 빠름
장점은 역시 방대한 생태계임. Civitai에 올라온 커스텀 모델, LoRA, 텍스처 인버전 등이 압도적으로 많음. 특히 애니메이션 스타일 쪽은 아직도 SD 1.5 기반 모델이 강세임.
단점은 확실함. 해상도가 낮고, 손가락이 6개 나오는 건 일상임. 텍스트 렌더링은 거의 불가능함. 2026년 기준으로 보면 교육용이나 빠른 프로토타이핑 정도로 포지션이 좁아진 상태임.
SD 1.5는 AI 이미지 생성의 교과서 같은 존재. 입문용으로는 여전히 좋음.
SDXL (Stable Diffusion XL) — 현재 가장 널리 쓰이는 주력 모델
SDXL 1.0은 2023년 출시 이후 2026년 현재까지도 프로덕션 환경에서 가장 많이 쓰이는 모델임. 이유가 있음.
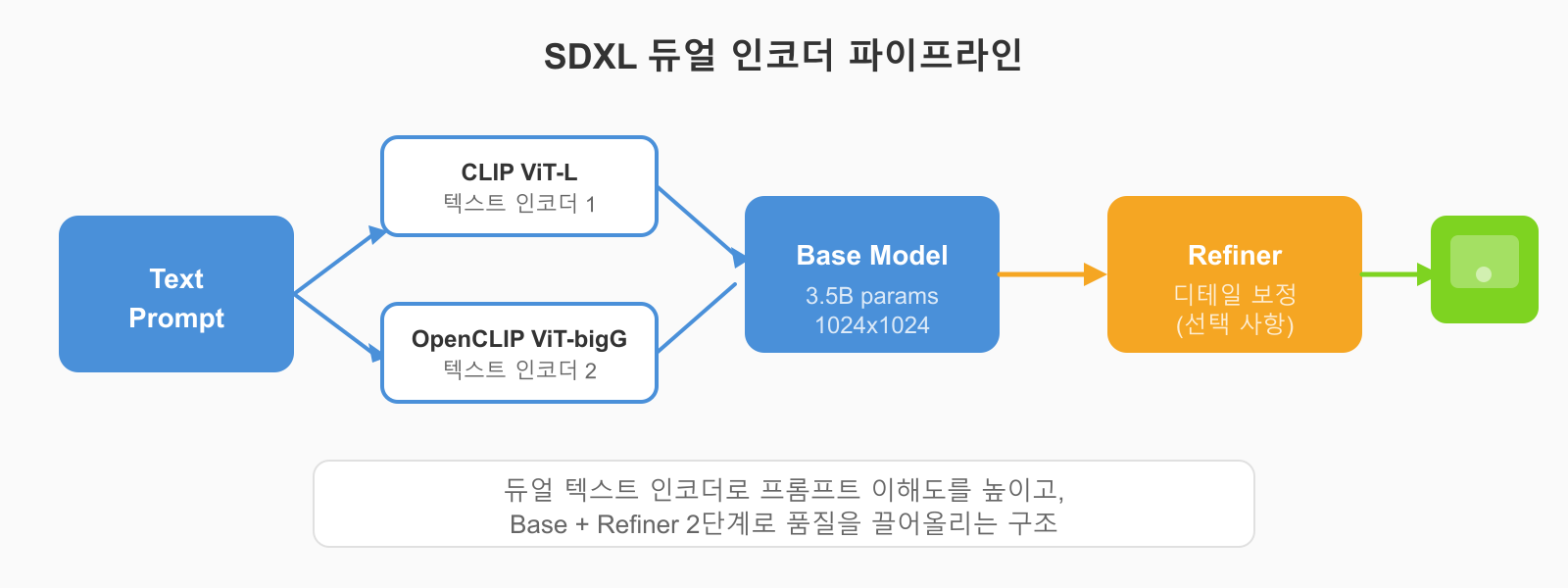
- 파라미터: 약 35억 개 (SD 1.5의 4배)
- 해상도: 1024x1024 기본
- VRAM: 8GB 이상 권장
- 특징: 듀얼 텍스트 인코더 (CLIP ViT-L + OpenCLIP ViT-bigG)
SDXL이 아직도 주력인 가장 큰 이유는 커뮤니티 에셋의 규모임. Civitai와 HuggingFace에 올라온 LoRA, ControlNet, 체크포인트 수가 압도적임. 뭘 하려고 해도 누군가 이미 만들어 놓은 게 있음
.
SDXL Turbo라는 변형도 있는데, 1~4 스텝만으로 이미지를 뽑아내는 경량 버전임. 실시간 미리보기에 유용함.
단점이라면 텍스트 렌더링이 여전히 약함.
그리고 Flux에 비하면 포토리얼리즘에서 디테일이 떨어짐. 하지만 스타일라이즈드 아트, 일러스트, 애니메이션 쪽에서는 여전히 SDXL이 강함.
Stable Diffusion 3.5 — Stability AI의 최신작
SD 3.5는 2024년 10월에 나온 모델임. MMDiT (Multimodal Diffusion Transformer) 아키텍처를 도입해서 기존 UNet 기반 SD와는 구조 자체가 다름.
- Large: 80억 파라미터, 최고 품질
- Large Turbo: Large의 증류 버전, 4스텝으로 생성
- Medium: 26억 파라미터, 소비자 하드웨어 최적화
- VRAM: 12GB 이상 권장 (Large 기준)
텍스트 렌더링 성능이 확 올라간 게 포인트임. 이미지 안에 글자를 넣을 수 있게 됐음. 프롬프트 이해도도 SD 1.5나 SDXL보다 훨씬 좋음.
다만 출시 초기에 생태계가 빈약했는데, 이제는 Stability AI가 직접 ControlNet(Blur, Canny, Depth)을 공개하면서 활용 폭이 넓어지는 중임. 연 매출 $1M 미만이면 상업용도 무료(Stability AI Community License)인 것도 장점.
SD 3.5는 SDXL의 후속이지만, 커뮤니티 에셋 면에서는 아직 SDXL을 못 따라잡은 상태임.
Flux.1 — Black Forest Labs가 만든 게임 체인저
Flux.1은 Stable Diffusion의 원래 개발자들이 세운 Black Forest Labs에서 만든 모델임. 2024년 출시 이후 ComfyUI 생태계를 완전히 바꿔놓았음.

Flux.1 변형들
| 모델 | 파라미터 | 특징 | 라이선스 |
|---|---|---|---|
| Schnell | 12B | 1~4스텝 초고속 생성 | Apache 2.0 (완전 오픈) |
| Dev | 12B | 고품질 + 오픈 웨이트 | 비상업 라이선스 |
| Pro | 12B | 최고 품질 | API 전용 |
Flux.1이 대단한 이유
포토리얼리즘에서 Flux는 SDXL을 확실히 이김. 피부 질감, 직물 질감, 금속 반사 같은 디테일이 다른 차원임. 그리고 가장 큰 차별점은 텍스트 렌더링. Flux는 이미지 안에 깔끔하게 글자를 넣을 수 있음. 포스터, 목업, 인포그래픽 만들 때 매우 유용함.
단점은 하드웨어 요구사항임. 12B 파라미터라서 VRAM 12GB는 최소, 쾌적하게 쓰려면 16GB 이상 필요함. 생성 속도도 SDXL보다 느림.
Flux.2 (2025년 11월 출시)
최근에는 Flux.2 시리즈도 나왔음. 최대 10개 참조 이미지를 동시에 활용할 수 있고, 아이덴티티 유지, 제품 디테일 유지 같은 기능이 강화됐음. Flux.2 [dev]는 오픈 웨이트로 공개되어 ComfyUI에서 바로 사용 가능함.
또 Flux.1 Kontext [dev]라는 모델도 있는데, 이미지 편집과 컨텍스트 기반 수정에 특화된 모델임. 기존 이미지를 참조해서 스타일이나 요소를 수정하는 데 최적화되어 있음.

ControlNet — 구도를 내 맘대로
ControlNet은 이미지 생성의 구도와 구조를 정밀하게 제어하는 모델임. 단독으로 쓰는 게 아니라 베이스 모델(SDXL, Flux 등)과 함께 쓰는 보조 모델임.

주요 전처리기(Preprocessor)
- Canny: 에지 검출. 윤곽선 기반 구도 제어
- Depth: 깊이맵. 원근감과 공간감 유지
- OpenPose: 인체 포즈 감지. 캐릭터 자세 지정
- Scribble: 간단한 스케치를 이미지로 변환
- Segmentation: 영역별 색 분리. 구역 지정 생성
- Normal Map: 표면 질감과 조명 방향 제어
베이스 모델별 ControlNet 지원 현황
SDXL용 ControlNet은 가장 풍부함. 공식 모델은 없지만 커뮤니티에서 만든 모델이 많음. ControlNet Union이라는 통합 모델도 있어서 하나의 모델로 여러 전처리기를 쓸 수 있음.
Flux용 ControlNet은 XLabs-AI, InstantX, Jasperai 등이 개발한 모델들이 있음. Canny, Depth, Surface Normal 등을 지원함. 아직 SDXL만큼 다양하지는 않지만 빠르게 늘어나는 중임.
SD 3.5용 ControlNet은 Stability AI가 직접 Blur, Canny, Depth 3종을 공개함. 80억 파라미터 기반이라 품질은 좋음.
IP-Adapter — 이미지 한 장으로 스타일 전이
IP-Adapter는 참조 이미지의 스타일이나 주제를 새 이미지에 입히는 모델임. 쉽게 말하면 "이미지 1장짜리 LoRA" 같은 존재임.
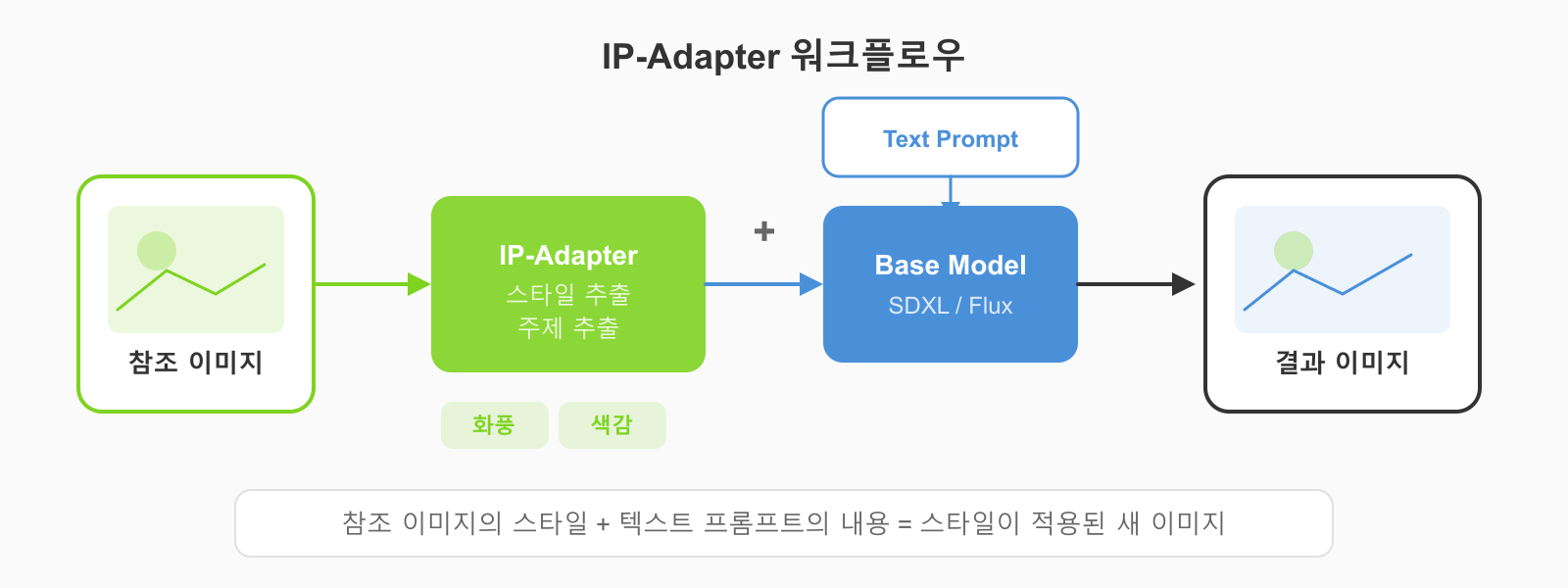
주요 기능
- 스타일 전이: 참조 이미지의 화풍, 색감, 분위기를 복사
- 얼굴 전이 (FaceID): 참조 얼굴을 새 이미지에 적용
- 구도 참조: 참조 이미지의 레이아웃을 유지하면서 새 이미지 생성
ComfyUI에서는 ComfyUI_IPAdapter_plus 커스텀 노드를 통해 사용함. V2에서는 Unified Loader가 도입돼서 모델 관리가 편해졌음. 다만 V1에서 V2로 업그레이드하면 기존 워크플로우가 호환 안 됨. 이건 좀 아쉬운 부분.
ControlNet과 함께 쓰면 시너지가 엄청남. ControlNet으로 구도를 잡고, IP-Adapter로 스타일을 입히는 조합이 ComfyUI에서 가장 인기 있는 워크플로우 중 하나임.
LoRA — 가성비 최고의 파인튜닝
LoRA (Low-Rank Adaptation)는 거대 모델을 완전히 재학습하지 않고, 소량의 파라미터만 추가 학습시키는 기법임. ComfyUI에서 가장 많이 활용되는 개념 중 하나임.
LoRA의 핵심
- 용량: 보통 10~200MB (전체 모델 대비 극히 작음)
- 학습 비용: 소비자 GPU로도 학습 가능
- 적용 방식: 베이스 모델 위에 얹어서 사용
- 효과: 특정 스타일, 캐릭터, 컨셉을 모델에 주입
예를 들어 "지브리 스타일 LoRA"를 SDXL에 얹으면, SDXL이 지브리풍 그림을 그리게 되는 원리임. 여러 LoRA를 동시에 적용하는 것도 가능함.

베이스 모델별 LoRA 상황
- SD 1.5: LoRA가 가장 많음. Civitai에 수만 개
- SDXL: 두 번째로 많음. 주력 생태계
- Flux: 빠르게 늘어나는 중. HuggingFace와 Civitai에서 Flux 네이티브 LoRA가 계속 올라오고 있음
- SD 3.5: 아직 상대적으로 적음
LoRA는 "모델을 내 것으로 만드는" 가장 효율적인 방법임. ComfyUI 쓴다면 반드시 알아야 함.
모델별 한눈에 비교

| 항목 | SD 1.5 | SDXL | SD 3.5 Large | Flux.1 Dev |
|---|---|---|---|---|
| 파라미터 | 0.86B | 3.5B | 8B | 12B |
| 기본 해상도 | 512x512 | 1024x1024 | 1024x1024 | 1024x1024 |
| 최소 VRAM | 4GB | 8GB | 12GB | 12GB |
| 포토리얼리즘 | 낮음 | 중간 | 높음 | 최고 |
| 텍스트 렌더링 | 불가 | 약함 | 좋음 | 최고 |
| 생성 속도 | 최고 | 빠름 | 보통 | 느림 |
| LoRA 생태계 | 최대 | 많음 | 적음 | 성장 중 |
| ControlNet | 풍부 | 풍부 | 일부 | 성장 중 |
| 라이선스 | CreativeML | CreativeML | Community | Apache/비상업 |
어떤 모델을 써야 할까?
- 빠른 프로토타이핑, 가벼운 작업 → SD 1.5
- 범용 작업, 스타일라이즈드 아트, 가장 넓은 생태계 → SDXL
- 포토리얼리즘, 텍스트 포함 이미지 → Flux.1 Dev
- 최신 기능 + 공식 ControlNet 지원 → SD 3.5
- 완전 오픈소스 + 상업용 → Flux.1 Schnell (Apache 2.0)
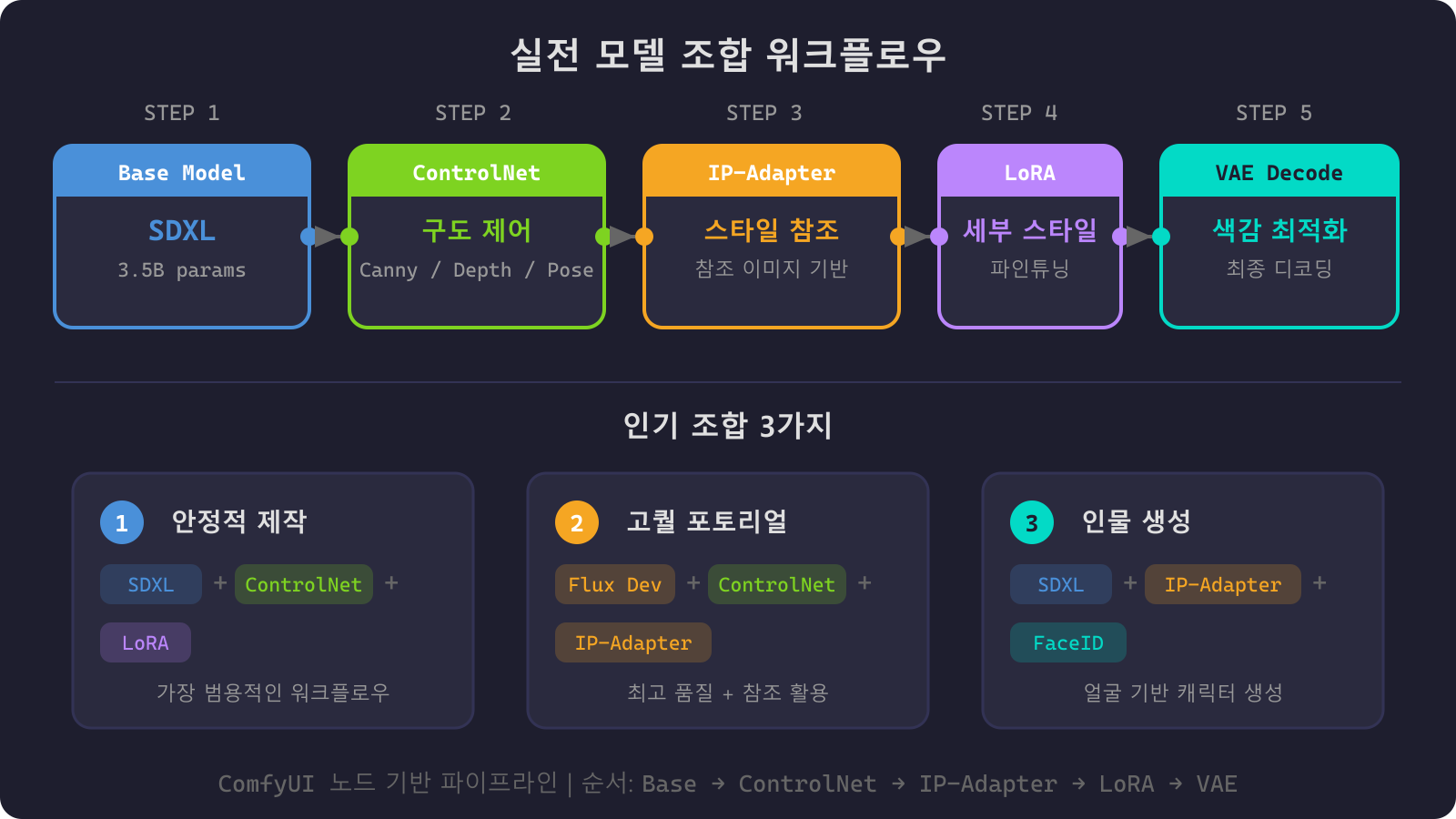
실전 조합 팁
ComfyUI의 진짜 힘은 이 모델들을 조합해서 쓰는 것에 있음.
가장 인기 있는 조합:
- SDXL + ControlNet + LoRA: 구도 잡고 → 스타일 입히기. 가장 안정적
- Flux.1 Dev + ControlNet + IP-Adapter: 고퀄 포토리얼 + 참조 이미지 활용
- SDXL + IP-Adapter + FaceID: 인물 사진 기반 생성
워크플로우 팁:
- 먼저 베이스 모델 결정 (용도에 맞게)
- ControlNet으로 구도/포즈 잡기
- IP-Adapter로 스타일/참조 적용
- LoRA로 세부 스타일 조정
- VAE로 색감 최적화
이 순서만 기억하면 ComfyUI에서 왠만한 건 다 만들 수 있음.
마무리
ComfyUI의 모델 생태계는 계속 진화하고 있음. 2026년 기준으로 보면 SDXL이 여전히 가장 안정적인 주력이고, Flux가 품질 면에서 앞서 나가는 중임. SD 3.5는 공식 지원이 늘어나면서 입지를 다지는 중이고, SD 1.5는 레거시이지만 가볍고 빠른 장점이 있음.
결국 "최고의 모델"은 없음. 용도에 맞는 모델을 고르는 게 핵심임. 이 글이 모델 선택에 도움이 됐으면 좋겠음.
GA4를 제대로 배우고 싶다면?
데이터 분석의 기본부터 실전까지, GA4 강의를 무료로 들을 수 있음.
jit.camp 에서 지금 바로 시작해보셈!